Tutorial Ceph Storage Cluster : Troubleshooting
February 27, 2019
Mengoperasikan Ceph Storage Cluster terkadang memang sulit, apalagi bagi kita yang belum banyak pengalaman dan ilmu administrasi nya. Terkadang pada saat pembuatan cluster atau saat mengoperasikan cluster, ada saatnya cluster mengalami Error.

Menggunakan Perintah Diagnostik
Terkadang kita tidak tahu apa yang Error, tentu kita ingin sekali mengetahui penyebab errornya dengan harap bisa memperbaiki error tersebut. Perintah diagnostik tentu akan sangat membantu troubleshooting. Berikut beberapa perintah yang dapat digunakan untuk diagnostik ceph storage cluster.
1. Mengecek Cluster
$ ceph status
Perintah ceph status berguna untuk melihat summarize kondisi cluster.


2. Mengecek Kesehatan Cluster
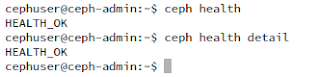
Cluster yang tidak sehat bisa membuat berjalan nya cluster tergangu. Cluster yang tidak sehat bisa dilihat dengan status nya yang HEALH_WARN dan HEALTH_ERR.
$ ceph health $ ceph health detail
Perintah ceph health atau ceph health detail berguna untuk melihat kondisi cluster.
3. Ceph {Nama Daemon} Dump

Selain OSD yang out dapat menyebabkan health error, penyebab lain error bisa berupa OSD dari Disk yang penuh, jadi kita perlu tahu OSD mana yang penuh.

4. Cek Status Daemon Masing Masing Node
Daemon yang tidak berjalan dengan baik dapat menyebabkan kegagalan cluster, seperti Monitor yang tergabung dengan quorum tapi tidak berjalan. Bisa juga OSD yang gak mau jalan atau gagal jalan di Node.



Troubleshooting
A. Clock Skew pada Monitor
Monitor merupakan bagian yang penting dalam Ceph Storage Cluster. Tugas monitor lah yang menyimpan versi cluster map terakhir. Jadi kalau monitor mengalami clock skew, hal ini tentu akan menggangu berjalan nya cluster. Pertama, clock skew ini apa?
Dari yang dapat saya ambil dari Wiki tentang Clock Skew, ini merupakan sebuah fenomena yang terjadi pada sistem yang tersinkronisasi. Gejala nya berupa waktu yang tidak tersinkronisasi pada komponen sistem dengan yang lain.
Pada Ceph, Clock Skew bisa terjadi karena waktu yang ada pada Monitor A berbeda dengan yang ada pada Monitor B. Kalau menggunakan 1 Monitor saja, saya rasa Clock Skew mustahil terjadi. Maksimum toleransi perbedaan waktu antar monitor adalah 0.05 detik atau 50 millidetik. Sebernarnya angka ini bisa diubah dengan menambahkan opsi "mon-clock-drift-allowed <detik>" pada ceph.conf. Namun, konfigurasi seperti ini saya tidak disarankan.
Mengecek apakah ada Clock Skew pada Monitor, bisa dilakukan dengan menggunakan perintah diagnostik seperti :

Mengatasi masalah Clock Skew, cara yang paling mudah adalah dengan mensinkronisasikan waktu dengan Server NTP. Berikut daftar NTP yang ada di Indonesia :

**Disarankan menggunakan NTP Server di Indonesia karena koneksi nya bisa lebih cepat dan meminimalkan delay time (ms).
Untuk menggunakan NTP Server ini, konfigurasikan hal-hal berikut pada setiap Monitor yang tergabung kedalam Quorum.
1. Install paket ntpdate dan ntp
3. Cek waktu/tanggal server

Cara Kedua kita bisa mengatur waktu nya secara manual pada masing masing Monitor, tapi ini harus dilakukan dengan sangat cepat. Metode ini tidak disarankan oleh saya, karena ribet.
B. Too Many PGs Per OSD
Perhitungan yang salah pada saat perencanaan OSD pada Ceph Cluster dapat berimbas pada performa OSD yang kurang. Placement Groups atau PGs merupakan metode yang digunakan Ceph untuk menyimpan data dalam grup-grup penyimpanan tertentu. Sebuah PGs tidak hanya tersimpan di satu OSD saja, namun 1 PGs dapat tersebar di 2 OSD (lihat Arsitektur Ceph).
Kembali ke topik, masalah "Too Many PGs Per OSD" bisa disebabkan oleh penambahan Pool yang tidak terduga sebelum perencanaan OSD dan bisa juga disebabkan perhitungan yang salah pada total PGs yang seharusnya ada pada setiap OSD. Untuk menghindari hal ini bisa menggunakan Rumus yang sudah dibagikan di docs official milik Ceph. Rumus nya :
Selain perintah yang ada diatas, ada juga sebuah trik yang dapat digunakan untuk mengubah jumlah placement group. Hanya berbekal pool, perintah copy isi pool ke pool lain, dan perintah menaikan jumlah pg, masalah Too Many PGs per OSD dapat terselesaikan.
Pertama cek OSD dalam Cluster,
Cek OSD yang PGs nya kebanyakan atau lebih dari 300 atau kurang dari 30.
Pool yang baru dibuat nanti akan dijadikan tempat menyimpan data Pool lama.
Salin isi pool yang lama ke yang baru.
Pool lama yang sudah selesai di salin bisa dihapus atau disimpan.
Ubah nama pool baru ke pool lama.
Lakukan beberapa konfigurasi pg_num dan pgp_num untuk pool lama agar PG dan PGP nya sesuai dengan kondisi Cluster saat ini.
Referensi
Ceph : Troubleshooting Monitor
Ceph: Too Many PGs per OSD
Sync Time with NTP in Linux
Wiki : Clock Skew

3. Ceph {Nama Daemon} Dump
$ ceph {daemon} dump
$ ceph {daemon} dump --format=xml-pretty
Perintah ini berguna untuk melihat map masing-masing daemon seperti mon map, osd map, mds map, placement group (pg) map, dan mgr map (khusus versi luminous keatas). Contoh pengunaanya seperti ini. Gunakan opsi --format untuk mengubah format output, format yang tersedia ada xml, xml pretty, json, json-pretty, dan plain.


4. Melihat Status OSD
Terkadang Error yang terjadi bisa karena OSD yang out (weight=0) dari cluster. Atau Host yang sedang down. Untuk dari itu kita perlu tahu apa yang terjadi dengan OSD kita. Perintah yang dapat digunakan untuk melihat status OSD seperti ini.
Terkadang Error yang terjadi bisa karena OSD yang out (weight=0) dari cluster. Atau Host yang sedang down. Untuk dari itu kita perlu tahu apa yang terjadi dengan OSD kita. Perintah yang dapat digunakan untuk melihat status OSD seperti ini.
$ ceph osd tree

Selain OSD yang out dapat menyebabkan health error, penyebab lain error bisa berupa OSD dari Disk yang penuh, jadi kita perlu tahu OSD mana yang penuh.
$ ceph osd df

4. Cek Status Daemon Masing Masing Node
Daemon yang tidak berjalan dengan baik dapat menyebabkan kegagalan cluster, seperti Monitor yang tergabung dengan quorum tapi tidak berjalan. Bisa juga OSD yang gak mau jalan atau gagal jalan di Node.
$ pushd /; sudo service ceph* status; popd

5. Mengecek Pool
Konfigurasi pool yang salah dapat berujung pada tidak sehat nya cluster. Berikut perintah untuk mendiagnosa Pool pada ceph storage cluster.
$ ceph df
Perbedaan perintah diatas dengan perintah ceph osd df ada pada output perintah nya. Kalau ceph osd df mengeluarkan output berupa informasi penggunaan disk, berat, serta total placement group per osd. Sedangkan perintah ceph df akan mengeluarkan output berupa informasi mengenai Pool pada cluster.

6. Mengecek CRUSH Map
$ ceph osd crush dump
Mengubah CRUSH map yang awalnya default diperlukan apabila kita ingin melakukan konfigurasi/administrasi penuh dengan Ceph Storage Cluster. Untuk mengecek CRUSH map gunaan perintah diatas.
Note : Seiring menggunakan ceph-deploy untuk deployment atau scaling Ceph Storage Cluster, CRUSH map akan berubah-ubah.
Note : Seiring menggunakan ceph-deploy untuk deployment atau scaling Ceph Storage Cluster, CRUSH map akan berubah-ubah.

Troubleshooting
A. Clock Skew pada Monitor
Monitor merupakan bagian yang penting dalam Ceph Storage Cluster. Tugas monitor lah yang menyimpan versi cluster map terakhir. Jadi kalau monitor mengalami clock skew, hal ini tentu akan menggangu berjalan nya cluster. Pertama, clock skew ini apa?
Dari yang dapat saya ambil dari Wiki tentang Clock Skew, ini merupakan sebuah fenomena yang terjadi pada sistem yang tersinkronisasi. Gejala nya berupa waktu yang tidak tersinkronisasi pada komponen sistem dengan yang lain.
Pada Ceph, Clock Skew bisa terjadi karena waktu yang ada pada Monitor A berbeda dengan yang ada pada Monitor B. Kalau menggunakan 1 Monitor saja, saya rasa Clock Skew mustahil terjadi. Maksimum toleransi perbedaan waktu antar monitor adalah 0.05 detik atau 50 millidetik. Sebernarnya angka ini bisa diubah dengan menambahkan opsi "mon-clock-drift-allowed <detik>" pada ceph.conf. Namun, konfigurasi seperti ini saya tidak disarankan.
Mengecek apakah ada Clock Skew pada Monitor, bisa dilakukan dengan menggunakan perintah diagnostik seperti :
$ ceph status # atau ceph -s

Mengatasi masalah Clock Skew, cara yang paling mudah adalah dengan mensinkronisasikan waktu dengan Server NTP. Berikut daftar NTP yang ada di Indonesia :

**Disarankan menggunakan NTP Server di Indonesia karena koneksi nya bisa lebih cepat dan meminimalkan delay time (ms).
Untuk menggunakan NTP Server ini, konfigurasikan hal-hal berikut pada setiap Monitor yang tergabung kedalam Quorum.
1. Install paket ntpdate dan ntp
$ sudo apt-get install ntpdate ntp -y2. Lakukan sinkronisasi waktu dengan ntp server
$ sudo ntpdate 0.id.pool.ntp.org**Disarankan menggunakan IP dari NTP server daripada menggunakan hostname NTP server.
3. Cek waktu/tanggal server
$ sudo hwclock; sudo date;4. Cek kembali status cluster
$ ceph status # atau ceph -sPastikan kondisi cluster baik-baik saja, caranya dengan melihat apakah error clock skew tadi sudah hilang dan status health (kesehatan) cluster menjadi HEALTH_OK.

Cara Kedua kita bisa mengatur waktu nya secara manual pada masing masing Monitor, tapi ini harus dilakukan dengan sangat cepat. Metode ini tidak disarankan oleh saya, karena ribet.
B. Too Many PGs Per OSD
Perhitungan yang salah pada saat perencanaan OSD pada Ceph Cluster dapat berimbas pada performa OSD yang kurang. Placement Groups atau PGs merupakan metode yang digunakan Ceph untuk menyimpan data dalam grup-grup penyimpanan tertentu. Sebuah PGs tidak hanya tersimpan di satu OSD saja, namun 1 PGs dapat tersebar di 2 OSD (lihat Arsitektur Ceph).
Kembali ke topik, masalah "Too Many PGs Per OSD" bisa disebabkan oleh penambahan Pool yang tidak terduga sebelum perencanaan OSD dan bisa juga disebabkan perhitungan yang salah pada total PGs yang seharusnya ada pada setiap OSD. Untuk menghindari hal ini bisa menggunakan Rumus yang sudah dibagikan di docs official milik Ceph. Rumus nya :
Rumus Menghitung Total PG dalam Cluster :Rumus Lainnya :Total PGs = (Jumlah Total OSD * 100) / Jumlah Replika Note : Hasil dari perhitungan harus mendekati eksponen angka 2. Contohnya saya dapat hasil 1000, maka saya harus mengatur agar nanti jumlah PG menjadi eksponen 2 dari 1000, yakni 1024.
Rumus Menghitung Total PG per Pool:Perintah yang dapat digunakan untuk menangani masalah ini adalah :Total PGs = (Jumlah Total OSD * 100) / Jumlah Replika / Jumlah Pool Note : Hasil dari perhitungan harus mendekati eksponen angka 2. Contohnya saya dapat hasil 28, maka saya harus mengatur agar nanti jumlah PG per Pool menjadi eksponen 2 dari 28, yakni 32.
ceph osd pool create <pool-name> <pg-number> <pgp-number> # Digunakan untuk membuat pool dengan mendeklarasikan jumlah pg dan jumlah pgp
ceph osd pool get <nama_pool> pg_num # Digunakan untuk mendapatkan jumlah pg pada pool
ceph osd pool get <nama_pool> pgp_num # Digunakan untuk mendapatkan jumlah pgp pada pool
ceph osd pool get <nama_pool> all # Digunakan untuk mendapatkan semua informasi mengenai pool
ceph osd pool set <nama_pool> <jumlah_pg> # Digunakan untuk menaikan jumlah pg pada pool
ceph osd pool set <nama_pool> <jumlah_pgp> # Digunakan untuk menaikan jumlah pgp pada pool
Note : Perintah ... set ... pg_num | pgp_num hanya dapat menaikan jumlah pg dan pgp, tidak untuk mengurangi nya.
Selain perintah yang ada diatas, ada juga sebuah trik yang dapat digunakan untuk mengubah jumlah placement group. Hanya berbekal pool, perintah copy isi pool ke pool lain, dan perintah menaikan jumlah pg, masalah Too Many PGs per OSD dapat terselesaikan.
Pertama cek OSD dalam Cluster,
Cek OSD yang PGs nya kebanyakan atau lebih dari 300 atau kurang dari 30.
$ ceph dfBuat Pool Baru,
Pool yang baru dibuat nanti akan dijadikan tempat menyimpan data Pool lama.
$ ceph osd pool create pool-baru 32 32Copy Pool Lama ke Baru,
Salin isi pool yang lama ke yang baru.
$ rados cppool pool-lama pool-baruHapus Pool Lama
Pool lama yang sudah selesai di salin bisa dihapus atau disimpan.
$ ceph osd pool rm pool-lama pool-lama --yes-i-really-really-mean-itRename Pool Baru => Lama,
Ubah nama pool baru ke pool lama.
$ ceph osd pool rename pool-baru pool-lamaKonfigurasi Pool Lama,
Lakukan beberapa konfigurasi pg_num dan pgp_num untuk pool lama agar PG dan PGP nya sesuai dengan kondisi Cluster saat ini.
$ ceph osd pool set pool-lama pg_num | pgp_numLakukan hal yang sama pada setiap pool agar PGs per OSD menjadi kurang dari 300 dan lebih dari 30. Sekian saja trik menyiasati error "Too Many PGs per OSD" pada Ceph Storage Cluster. Semoga bermanfaat.
Referensi
Ceph : Troubleshooting Monitor
Ceph: Too Many PGs per OSD
Sync Time with NTP in Linux
Wiki : Clock Skew
--- On Going ---
0 komentar
Berkomentarlah sesuai dengan topik yang sedang dibahas. Komentar yang berisi Link aktif akan di hapus oleh Admin. Terima Kasih.